Authors:
Kevin Chan
Staff Software Developer, Machine Learning at Kinaxis
Bill Sun
Software Developer 2, Machine Learning at Kinaxis
Continuous integration, or CI (sometimes called CI/CD along with continuous deployment), is an automatic pipeline for quick testing, integration, and deployment of software applications to enhance software delivery in modern software development. For the purposes of this blog, we will stick to discussing the CI portion.
A typical CI for a traditional user software application has elements such as code formatting, automated testing (unit and integration testing, contract validation), and deployment. They should enhance the developer experience by automation, improving productivity, ensuring clean and working code, and reducing errors / preventing bugs. A CI typically comes with a code repository, where is it is run on every code commit. It is usually in the form of a pipeline / workflow defined by a yaml file. Common tools include GitHub Actions and CircleCI.
Before we go into the specifics, we’d like to clarify that CI/CD refers to a set of development practices that enable the rapid and reliable delivery of code changes, while DevOps (development operations) is a collection of ideas, practices, processes, and technologies that allow development and operations teams to work together to streamline software development. On the other hand, MLOps (machine learning operations) is a data science process that involves rapid testing and deployment of machine learning models. The CI is an implementation of both paradigms.
Machine learning forecasting applications, such as a demand forecasting system for supply chain, have more specialized requirements for a good CI pipeline. It needs to satisfy the requirements of MLOps. These systems need to ensure an accurate and timely forecast in addition to being logically correct. We will dive into the details here.
More recently, with the advent of Large Language Models (LLMs), generative AI, and all the software applications that come with it, the requirement for a CI is being extended further to accommodate the unique features and capabilities of LLMs, and satisfy the requirements of LLMOps (LLM operations), which will be discussed in a future blog post.
At Kinaxis, we have experience working on various traditional software systems, machine learning forecasting systems, and more recently, LLM-based systems. In this blog post, we discuss what makes a good CI, and how these requirements change with ML and artificial intelligence software applications.
First of all, what makes a good CI? The CI is a critical component in modern software development, enhancing both developer experience and code quality. It automates numerous tasks, allowing developers to focus on design and logic rather than manual processes. CI provides an abstraction of testing and production environments, ensuring consistency and simplifying complex configurations. This system enforces code quality, implements observability, and improves both internal and external customer experiences. As software applications increasingly incorporate AI and machine learning, CI requirements continue to evolve. The extent of CI implementation should be tailored to the specific needs of each project, considering factors such as software criticality and user base. Ultimately, a well-designed CI system serves as a bridge between software development and quality assurance, evolving alongside the code it supports.
Complexities of machine learning and how to design a CI for ML forecasting
Let’s discuss a case with a traditional, supervised machine learning workflow. Think of any machine learning forecasting system, consisting of data flowing in (data ingestion), data processing / feature engineering, model training, model optimization (hyperparameter tuning), inference / forecasting, and in some cases, model explanation / post-analysis.
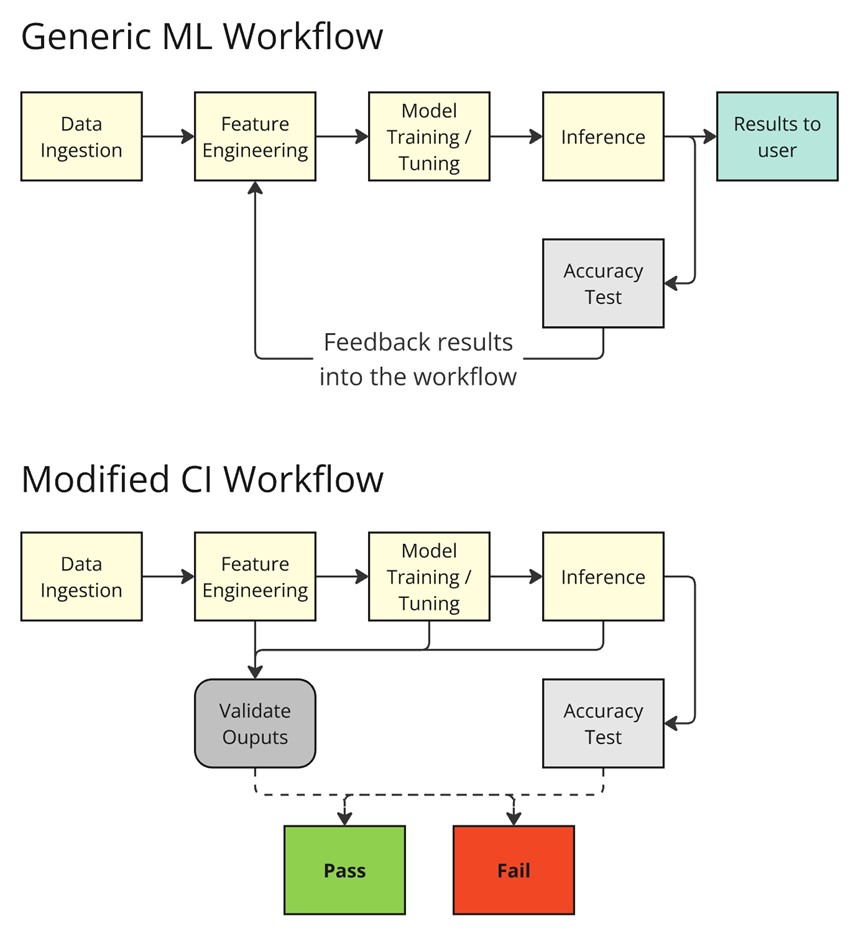
One key feature where machine learning differs from traditional software is the need to ensure the accuracy of the system or models (whether it is a forecast or recommendation), in addition to the logical accuracy of the code. This presents a challenge since the accuracy measured on a continuum (i.e., the result is a probability or a range of values rather than a fixed value), whereas the logical accuracy is often discrete (e.g., branches or conditions) and can be easily verified. A further challenge is that the forecast accuracy can change over time with changes to the data quality, data processing, machine learning model training and tuning.
There can also be a much larger cost associated with an ML pipeline as the feature generation and training can require a lot of resources. If hyperparameter tuning is also a part of the CI pipeline, then the cost can increase substantially as it is generally the heaviest portion of an ML pipeline.
Thus, in addition to the usual requirements discussed earlier (automation, testing, deployment, etc.), the machine learning CI needs to be able to measure forecast accuracy and changes in accuracy metrics over time (trends, outliers, etc.). We also need to keep in mind cost and performance, as well as tracking model degradation.
Most machine learning models involve the process of minimizing a loss function, which translates to maximizing the accuracy of our predictions matching the real data. As with any minimization problem, there can be local minimums that we can fall into that differ based on the starting conditions. In the case of ML models, this can be affected by the initial random seed, the underlying data, and the features that are used in the model.
The CI and integration testing with ML models has similarities with many other systems whose core workflows involve the creation of artifacts for later use, and the use of those artifacts. In the case of ML models, the artifact creation is heavily data dependent, and the use of the artifact is also heavily data dependent. The output of the predictions will change if the data changes, or if any of the data processing changes, irrespective of any changes to the model itself.
A more traditional test would be to use fixed data and a fixed set of features in the integration testing, with the hope that the predictions are also fixed in nature. It is difficult to add new edge cases to this type of testing as the predictions can be quite different with an additional data point while having the same predictive accuracy.
To this end, in an ML focused CI, we need to bring in the concept of accuracy as a byword for having a metric that we measure against from CI run to CI run.
To ensure that changes in any part of the ML workflow does not negatively affect the overall accuracy of the predictions, we'll need to be able to compare current runs with older runs. This feedback loop of an MLOps production pipeline is a core concept that needs to also exist in the CI pipeline. This process will differ between traditional supervised ML models and LLMs, as the conceptual understanding of accuracy differs between them.
There are a few things to keep in mind for the feedback loop in the CI:
- There must be a known source of truth with respect to the accuracy, such as the artifacts from the main branch.
- There will be parallel runs with artifacts from different branches, and these should not conflict with each other.
- There must be an acceptable range for test results involving ML.
- Depending on the model, there may be random fluctuations coming from the probabilistic nature of the model.
- A small change in the data should not affect the predictive power of the model.
- There must be a way to override the accuracy test in the CI to allow lower accuracy runs to merged in.
- There will be circumstances from some required changes that will cause the tests to fail due to a lowered accuracy measurement, provided that this is a known and acceptable degradation.
- For example, new data that is more challenging to the model, but is more realistic, or a drastic speed-up in training time at the detriment of lower accuracies.
We have been discussing ML models that are on a per client or per user basis, not general consumption models. If they are general models, your main CI pipeline can also act as your deployment pipeline, and that models that are trained in your CI can be your final models. For the client-specific models, your CI has to be generic with anonymized data, which means that the accuracy metrics used are of a relative nature. For general consumption models, the accuracy metric may be strict with little leeway, as it should be expected that you will never deploy a model into production that has not passed the CI verification test. The training data used in the CI for these general consumption models often overlaps or is exactly the data used to train the production model. The process of verifying the accuracy of an LLM based model has its own challenges as the predictions, by their nature, are not deterministic. However, the needs of the CI workflow stay the same, with the need for a feedback loop and careful understanding of the data ingestion, processing, and usage.
In summary, we can see that the inclusion of a machine learning workflow into a CI introduces new complexities that are neither necessary nor expected when dealing with a more traditional software system. The primary mover of these complexities is simply the probabilistic nature of the machine learning domain, leading to a needed change in the testing strategies when determining what is considered a “pass”. While much can be covered with known unit testing strategies, the needs of the overall end to end workflow forces us to change the way we look at the CI. In this way, we need to be flexible in the artifacts we store in the CI, the design of the CI workflow, and the data we use for testing.
In essence, there is no perfect CI. It can only be good enough.
Leave a Reply